تشکر استاد .
حالا عجله نیست . هر وقت ، وقت کردین .
بعد اینکه استاد در pdf ای که بنام database-masomi بود و قبلا دادید ، وقتی اجرا کردم ، پیام داد که فونت "Nazanin" باید نصب باشه . با اونکه این فونت را از اینترنت دانلود و نصب کردم اما در بعضی از شکل ها ، بصورت زیر هست و قاتی پاتیه . کاریش میشه کرد درست بشه؟
استاد ، در یه فیلم آموزشی درباره ی دیتابیس ، چیزهایی درس داد که حداقل در بقیه ی جاها ندیدم (این پست ، ممکنه خیلی زیاد بشه . شاید هم در 2 پست بشه که پیشاپیش معذرت میخوام از طولانی بودنش) .
بی زحمت ببینین چیزهایی که میگم ، درست هست ؟ :
اول اینکه درباره ی طراحی دیتابیس ، هم از اون کتاب database-masomi (تا اون جایی که خوندم . اما مطالبش خیلی سنگین هه . مخصوصا حدودا از صفحه ی 35 به بعد) و هم از این فیلم آموزشی ، اگه درک درستی ازشون داشته باشم :
1 - اولا اینکه یه چیزی بنام نمودار ER داریم که قبل از اینکه طراحی دیتابیس را پیاده سازی کنیم ، اول ، در این نمودار بهتره که شکل هاش را رسم کنیم (نمودار ER ، نسبت به برنامه نویسی بخوایم مثال بزنیم ، شبیه به زبان UML در برنامه نویسی برای طراحی دیتابیس میمونه) .
که در این نمودار ، نام جدول را در قسمت بالا و صفت هاشون (که همون نام ستون ها در دیتابیس هستند) را در بدنه ی شکل اش مینویسیم .
2 - دوما برای طراحی دیتابیس (بر پایه ی اصولی) ، اول باید موجودیت های متفاوت را تشخیص بدیم و هر موجودیت را درون جدولی متفاوت (نمودارِ ER ای متفاوت) قرار بدیم .
یک موجودیت ، چیزی هست که هم مفهومی جدای از موجودیتِ دیگه داره و مهمتر اینکه یک یا چند اطلاعات (یاهمون یک یا چند ستون در جدول ، یاهمون یک یا چند صفت در نمودار ER) را میشه براش در نظر گرفت (ولو اینکه حتی یک صفت داشته باشه) .
برای موجودیت ها اگه بخوایم مثالی از برنامه نویسی بزنیم ، موجودیت ها شبیه به کلاس ها (و enum ها) در برنامه نویسی هستند .
یعنی یه کلاس یا enum ، یه مجموعه ای از اعضایی دارند که این اعضاشون ، نسبت به مفهومِ کلاس های دیگه و اعضایِ اون کلاس های دیگه ، جدا هستند ، چون مفهوم و اعضای اون دو کلاس ، کلا با هم متمایز هست (البته شاید تقریبا گفت که بجز کلاس هایی که ارتباط وراثتی دارند) .
موجودیت ها هم تقریبا همینطورند و هر موجودیت و صفت های مربوط به اونها ، جدای از مفهومِ موجودیتِ دیگه و صفت های شون هست .
به عبارتی ساده تر ، یعنی هر جا (یا حداقل ، اغلب) در برنامه نویسی ، یه کلاس یا یه enum درست کردیم ، بخوایم اینها را در دیتابیس مدل سازی کنیم ، معادلِ هر کلاس یا enum در برنامه نویسی ، یک جدول (یا موجودیت) در دیتابیس ایجاد میکنیم .
3 - همونطور که گفته شد ، در نمودار ER ، چیزی بنام صفت داریم که همون ستون در جدول ها هستند .
مثلا یه نمودار ER در مثال این فیلم آموزشی :
که در نمودار ER ئه بالا ، دانشجو ، یک موجودیت در نمودار ER هست (که همون جدول در دیتابیس میشه) و ID ، شماره دانشجویی ، نام ، نام خانوادگی و ... ، صفت های این موجودیت در نمودار ER هستند (که همون ستون ها در جدول های دیتابیس میشن) .
4 - بهتر اینه که مقداری که برای یه ستون (صفت) وارد میکنیم ، بصورت اتمیک (تکی) یا همون تجزیه ناپذیر باشه . یعنی (تا جای ممکن) نشه یک مقدار از یک ستون را ، مجددا تجزیه کرد وگرنه بهتره که اون ستون را به عنوان یه موجودیت مجزا ، در جدولی دیگه قرار داد .
فرضا در شکل بالا ، اگه اشتباه نکنم ، صفت "آدرس" ، اتمیک نیست چون یه آدرس ، شامل نام کشور و استان و خیابان و کوچه و پلاک و ... هست که بهتر میبود اگه بصورت اصولی میخواست طراحی بشه ، آدرس ، در موجودیت و جدولی مجزا طراحی میشد . درست میگم؟
که البته دلیلش را قبلا گفته بودید که ممکنه مدرس ، بخاطر صرفه جویی در وقت ، این کار را نکرده باشه و ... .
------
بنابراین (مخصوصا در نکته شماره 2 که درباره ی موجودیت ها بود) ، فرضا اگه بخوایم اطلاعات مربوط به درس ای را برای دانشجو ثبت کنیم ، نباید در جدول بالا ، صفت ای بنام "درس" را اضافه کنیم . چون درس ، خودش یه موجودیتی جداگانه نسبت به موجودیت دانشجو هست و اطلاعات و صفت ها (ستون های) جدا ای داره .
مثلا اگه در برنامه نویسی ، یه کلاس "دانشجو" داشته باشیم ، اگه بخوایم داده های مربوط به "درس" را براش در نظر بگیریم ، نمیایم عضوی بنام "درس" را توی کلاس "دانشجو" بذاریم .
بلکه درس ، چون مفهومی مجزای از دانشجو هست ، کلاس "درس" و اعضای مربوطه اش مثل "عنوان" و "تعداد واحد درسی" و ... اش را جدا میکنیم و بعد در کلاس "دانشجو" ، عضو (پروپرتی) ای از نوع کلاس "درس" را درونش قرار میدیم .
معادلِ مدل سازیِ این قضیه در برنامه نویسی برای طراحی دیتابیس را هم این کار را میکنیم . یعنی یه جدول (موجودیت) برای "دانشجو" و یه جدول (موجودیت) ئه مجزای دیگه برای "درس" میسازیم و ستون ها (صفت ها) شون را براشون در نظر میگیریم (ولو حتی اگه یه جدول ، یه ستون براش در نظر بگیریم اما چون موجودیت مجزاست ، باید در یک جدول مجزا طراحی بشه) و ارتباط شون را مشخص میکنیم .
یعنی اولین کاری که میکنیم برای اینکه بدونیم آیا یه جدول جدید برای یک چیز طراحی کنیم یا نه ، دونستنِ موجودیت های مجزا هست (تا به تعداد اون موجودیت ها ، جدول طراحی کنیم) ، بعد از اون ، اینکه آیا در یه جدول ، برای یه صفت ، میشه چندین مقدار وارد کرد یا نه ، هم در ایجاد جدولی مجزا ، تاثیر داره (قضیه ی ارتباطات که در ادامه میگم) .
اما من قبلا ، موجودیت ها را به این حالت نمیشناختم ، فکر میکردم که برای ساختن موجودیت جدید ، فقط اگه در یه صفت و ستون ای ، بتونیم بیش از یک مقدار وارد کنیم ، فقط در اون صورت هست که اون ستون را به عنوان موجودیتی جدید ، در جدولی مجزا انتقال میدیم .
یعنی قبلا فکر میکردم که خوب ، حالا یه موجودیتی بنام "دانشجو" داریم و صفت "درس" ای را بهش اضافه میکنیم . چون این صفت "درس" ، برای هر دانشجو ممکنه بیش از یک مقدار بشه (یعنی بین دانشجو درس ، رابطه ی 1 به n هست . که البته توی این آموزش نکته ی خیلی خوبی گفت که تقریبا این نوع رابطه را هم برام زیر سئوال برد) ، فقط به همین دلیل هست که "درس" را در موجودیت و جدولی مجزا انتقال میدیم .
وگرنه فکر میکردم اگه رابطه ی دانشجو درس ، رابطه ای 1 به 1 باشه ، در این صورت ، لازم نیست که "درس" را به عنوان موجودیتی مجزا (در جدولی مجزا) طراحی کنیم . بلکه همون کافی هست که "درس" را به عنوان یه صفت (ستون) ، در جدول دانشجو قرار بدیم (که این نوع تفکرم ، اشتباه بود) .
درست میگم؟
ارتباطات و سئوالات مربوط بهش که خیلی مهم هست را در پست بعدی میگم .
سلامی مجدد استاد .
ادامه ی پست قبلی (بی زحمت ، مطالب زیر را برای درست بودنش ، چک میکنید) :
ارتباطات جداول در sql :
ارتباطات جداول در sql ، سه نوع هستن :
1- ارتباطات یک به یک :
وقتی به ازای هر سطر از یک جدول ، نیاز باشه که داده ای را فقط یه سطر از یه جدول دیگه ذخیره کنیم (یا کلا باهاش ارتباط برقرار کنیم) ، به این ارتباط ، ارتباط یک به یک در دو جدول میگن .
در این ارتباط ، داده هایی که در هر رکورد از ستون (صفت) از هر دو جدول قرار میگیره ، به هیچ عنوان نباید مشترک باشن (و فقط باید منحصر به فرد باشن) وگرنه نوع ارتباط شون ، "یک به n" یا "n به n" میشه .
در عکس زیر :
نوع رابطه را در نمودار ER ، درون لوزی رسم میکنن .
همچنین در عکس زیر :
رابطه ی جدول (در واقع موجودیت) "استاد" و جدول "درس" در دو عکسِ بالا ، زمانی "رابطه ی یک به یک" هست که فقط به ازای هر رکورد از استاد ، یک رکورد از درس (که هر دوشون نباید مشترک باشن) ، ثبت بشه .
یعنی تا زمانی رابطه ی "یک به یک" هست که اگه دو رکورد در جدول "استاد" داریم (رکورد با مقدار ID های شماره های 1 و 2 در جدول "استاد" داریم . مثلا ستون "نام" ، برای رکورد 1 ، مقدار "حسن" و برای رکورد 2 هم مقدار "قاسم" باشه) ، و همچنین دو رکورد در جدول "درس" داریم (برای این هم ، رکورد با مقدار ID های شماره های 1 و 2 در جدول "درس" داریم . مثلا ستون "عنوان" ، برای رکورد 1 ، مقدار "ریاضی" و برای رکورد 2 هم مقدار "فیزیک" باشه) ، اولا ، استادی بنام "حسن" ، فقط میتونه یه درس را بگیره (فرضا فقط میتونه درس "فیزیک" را بگیره) و دوما در صورتی که این درس "فیزیک" را قبلا ، استادِ دیگه ای نگرفته باشه (یعنی در صورتی میتونه "فیزیک" را بگیره که قبلا استادی بنام "قاسم" ، نگرفته باشه) .
همچنین یک درس هم فقط توسط یک استاد میتونه گرفته بشه . یعنی درس "فیزیک" ، فقط توسط یک استاد (مثلا استادی بنام "حسن") گرفته بشه .
یعنی در هیچ ارتباطی از رکوردهای دو جدول ، مشترک نشن .
وگرنه اگه مشترک بشن ، رابطه شون ، حداقل ، به "یک به n" (یا "n به n") تغییر پیدا میکنه .
- دوما ، نکته ی مهم در این نوع ارتباطِ یک به یک ، اینه که کلید خارجی را در کدوم یک از این جدول ها بذاریم (در واقع تعیین اینکه کدوم جدول ، جدول فرزند بشه) :
اطمینان 100 درصد ندارم اما تا جایی که تا حالا متوجه شدم ، اول باید ببینیم جدول اصلی مون کدوم هست . جدول اصلی مون هم احتمالا اون جدولی میشه که میخوایم بر پایه ی اون ، جستجو انجام بدیم .
یعنی فرضا اگه در اینجا بخوایم بر اساس نام (یا id و کلا بر اساس جدولِ) استاد ، جستجو مون را انجام بدیم ، پس جدول "استاد" ، جدول اصلی مون یا همون جدول والد مون میشه . بنابراین جدول مقابل ، یعنی جدول درس ، جدول فرزندمون میشه و چون جدول فرزند هم جدولی هست که ستون (صفت) با کلید خارجی درون اون جدول تعریف میشه ، پس اگه در شکل بالا ، بخوایم بر اساس جدول "استاد" جستجو کنیم (که در این صورت ، این جدول ، جدول والدمون میشه) ، پس کلید خارجیِ این جدول را درون جدول "درس" قرار میدیم .
یعنی مثل عکس بالا ، یه ستون (یا صفت ای) فرضا بنام "ProfessorID" یا بنام "MasterID" (فیلد قرمز در عکس دوم در بالا) را درون جدول درس قرار میدیم که این ستون ، به ستونِ ID در جدول "استاد" اشاره کنه و این ستون (قرمز رنگ) ، کلید خارجی هم هست .
- یا اینکه اگه میخوایم بدونیم که ستون (صفتی) که کلید خارجی داره را درون کدوم جدول قرار بدیم ، توسط مدل سازیِ شی گرا اش عمل میکنیم .
در این مدل سازی ، یک کلاس "استاد" و یک کلاس "درس" میسازیم . چون کلاس استاد ، عضوی از نوع کلاس "درس" را توی خودش داره(و این عضو در کلاس استاد ، به شی ای از کلاس "درس" اشاره میکنه) ، پس در مدل سازیِ دیتابیس اش هم همونطور که در بالا توضیح دادیم میشه . یعنی ستون "MasterID" ، به عنوان کلید خارجی ، در جدول "درس" قرار میگیره تا مثل مدل سازیِ شی گرا اش ، ستونِ ID در جدول "استاد" ، به ستون "MasterID" در جدول "درس" که کلید خارجی هست ، اشاره کنه (کلید اصلی هم که همیشه به کلید خارجی اشاره میکنه . البته در صورت وجود داشتن کلید خارجی در یک جدول دیگه) .
و کدش هم بصورت زیر میشه :
SQL:
SELECT Name, Family, Title
FROM tblMaster inner join tblLesson
ON tblMaster.ID = tblLesson.MasterID
- و اگه برعکس اش را بخوایم ، یعنی بخوایم طبق جدول "درس" ، جستجومون را انجام بدیم ، در این صورت ، ستونی به عنوان کلید خارجی ای در جدول "استاد" میذاریم که ID ئه جدول "درس" ، بهش اشاره کنه .
و البته شاید بشه که در هر دو جدول ، کلید خارجیِ جدول دیگه را قرار بدیم (نمیدونم) .
2 - ارتباطات یک به n (یا همون یک به چند) :
یعنی به ازای هر رکورد در یک فیلد ، یک یا چند رکورد در فیلدی دیگه بتونیم ذخیره کنیم . و در این نوع ارتباطات ، ستون و فیلدی که چندین مقدار را ممکنه به ازاش ثبت بشه را در جدولی مجزا منتقل میکنیم .
اولا وقتی از این نوع ارتباطات نام میبریم ، ممکنه به ازای هر رکورد ، فقط یک رکورد در فیلد و ستون متناظرش ثبت بشه (اما امکان این هست که چندین مقدار ثبت بشه) . مثل آرایه ها که ممکنه یک آیتم داشته باشن اما ممکنه چندین آیتم هم داشته باشن .
- نکته ای که بسیار مهم هست اینه که در این نوع ارتباطات ، کلید خارجی ، در سمت جدولی قرار میگیره که رابطه ی "n" داره . و به این ترتیب ، اون جدول ، جدول فرزند میشه .
یعنی اگه در شکل اول در این پست ، رابطه بصورت "1 : n" بود ، یعنی بصورت شکل زیر بود :
- اولا در شکل بالا ، یعنی به ازای یک "استاد" (یا همون به ازای یک رکورد از "استاد") ، بشه یک یا چند رکورد از "درس" را ثبت کرد . یا به عبارتی دیگه ، هر استاد بتونه چند تا درس را بگیره (مثلا استادی بنام "حسن" ، بتونه یک ، یا چند درسِ "ریاضی" و "فیزیک" و ... را بگیره) .
اما نکته ای که بسیار مهم در این رابطه هست اینه که هر درس ، فقط توسط یک استاد خاص ارائه بشه . یعنی یک درسی مثل فیزیک را چند تا استاد نتونن ارائه کنن (چون در این صورت ، رابطه ، "n به m" میشه) :
تصویر بالا ، رابطه ی یک به چند (یک به n) هست . چون هر استاد ، میتونه چند تا درس (که مشترک نباشن) را انتخاب کنه) .
اما تصویر بالا ، رابطه ی یک به چند نیست (رابطه ی یک به n نیست) .
بلکه رابطه ی چند به چند (یا n به m) هست . چون هر درس ، توسط چندین استاد (اون هم بصورت مشترک) انتخاب شده و همچنین برعکس (یعنی هر استاد ، چندین درس را گرفته اون هم بصورت مشترک) .
- و دوما ، کلید خارجی در اینجا (در 3 شکل بالاتر یا همون شکل شماره ی 3 در این پست) ، در جدولی که سمتِ n هست ، میذاریم . یعنی در عکس بالا ، ستونی به عنوان کلید خارجی را در جدول "درس" میذاریم و بنابراین جدولی که سمتِ n هست (در اینجا ، جدول "درس") ، در این نوع رابطه ، همیشه جدول فرزند میشه (یعنی مثل عکس دومی میشه که ستونی بنام "ID ئه استاد" یا همون "MasterID" را داشت) .
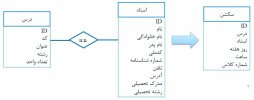
3 - ارتباطات n به m (یا چند به چند یا همون n به n) :
یعنی به ازای یک رکورد ، بتونیم چندین رکورد (در جدول دیگه) ، ذخیره کنیم و همچنین برعکس . اینکه اشتراکی هم بین شون بوجود بیاد ، اصلا مهم نیست .
یعنی هر استاد میتونه ، هر درسی را انتخاب کنه (هر چند تا که باشن) و هر درسی هم میتونه توسط هر استادی انتخاب بشن (هر چند تا که باشن) .
دقیقا مثل شکل بالا .
- نکته ی بسیار مهمی که هست اینه که در این نوع ارتباطات ، هیچ کلید خارجی ای درون یکی از این دو جدول قرار داده نمیشه (منظورم کلید خارجی ای هست که قرار باشه ارتباطات این دو جدول را مشخص کنه ها) . بلکه ستونِ مربوط به کلید خارجی (در این نوع رابطه) ، در جدولِ مجزایِ دیگه که بهش میگن جدول فصل مشترک ، قرار داده میشه :
در شکل بالا ، چون رابطه ی دو جدولِ "استاد" و "درس" ، رابطه ای n به n هست ، پس ستونِ کلیدِ خارجیِ مربوط به هر دو جدول ، درون جدولی دیگه قرار میگیره که در مثال بالا ، اسم این جدول ، "سکشن" نامیده شد .
و طبق شکل بالا ، دو ستونِ کلید خارجی ، در جدول "سکشن" قرار داره که ستونِ ID ئه دو جدول های "استاد" و "درس" ، بهشون اشاره میکنه (ستون های قرمز رنگ در جدول "سکشن" ، کلیدهای خارجی هستند) .
- در شکل بالا (در این نوع ارتباطات) ، برای ارتباط برقرار کردن بین جدول "استاد" و جدول "درس" ، چون جدول "استاد" ، با جدولِ "سکشن" ارتباط داره ، پس یک join ای بین این دو جدول مینویسیم و نتیجه اش را مجددا با join ای بین جدول "درس" و جدول "سکشن" خاتمه میدیم چون جدول "درس" هم با جدول "سکشن" ارتباط داره .
(اگه بعدش هم جدول دیگه ای هم خواستیم join کنیم ، بعد از اون میکنیم) .
در واقع برای این نوع ارتباطات (مثل شکل بالا) ، کافی هه از خودمون بپرسیم که بین کدوم جدول ها رابطه هست و نتیجه شون را با هم join کنیم .
یعنی برای ارتباط بین "استاد" و "درس" ، چه رابطه ی مشترکی بین شون قرار داره؟
یکی رابطه ی "استاد" و "سکشن" وجود داره . پس بین شون join میکنیم .
یکی دیگه هم رابطه ی "درس" و "سکشن" وجود داره . پس نتیجه ی قبلی را با این یکی join میکنیم .
و از اونجایی هم که inner join (بر خلاف left یا right join) ، فقط رکوردهای مشترک را بین دو جدول انتخاب میکنه ، اهمیتی نداره که کدوم جدول را برای join ، اول یا آخر بنویسیم . یعنی تقدم و تاخر برای inner join ، معنا نداره .
یعنی کد این نوع رابطه ، بصورت زیر میشه :
SQL:
SELECT Name, Family, Title
FROM tblMaster inner join tblSection ON tblMaster.ID = tblSection.MasterID
inner join tbLesson ON tblLesson.ID = tblSection.LessonID
این مطالب (که اغلب اش توسط اون کتاب و مخصوصا اون آموزش که بهش اشاره کردم گفته شد و همچنین درک من از این مطالب هست) ، درست هستن؟
سئوال را در پست بعدی میپرسم .
خیلی ممنون استاد .
ببخشید که خیلی طولانی شد .
اما استاد یه سئوال .
من فکر کردم ، دیدم اغلب ارتباطات ، ارتباطات چند به چند (n به n) هست .
بعضی جاها ممکنه رابطه ی یک به یک داشته باشیم .
اما من حداقل در مسائلی که تا حالا دیدم ، رابطه ی "یک یه چند" یا همون "1 به n" ندیدم باشه (یا خیلی کمتر دیدم).
الان در پست 108 ، رابطه ی "Customers" و "Recipt" (مشتری و سفارش) ، رابطه ی چند به چند نمیشه؟
دقیق نمیدونم . به نظرم میاد که رابطه شون چند به چند بشه .
چون مشتریِ شماره ی 1 (فرضا بنام "میلاد") ، میتونه چند تا سفارش بده (یعنی 2 تا ID ئه Recipt ، متلعق به مشتری شماره 1 که میلاد بود ، باشه) . مثلا میلاد ، سفارش چلوکباب با دوغ را میده .
اما آیا این 2 تا ID ئه سفارش مشتری (که نام غذاهاشون چلوکباب با دوغ بودن) ، توسط مشتریِ شماره ی 2 (که فرضا اسمش "محمود" هست) هم میتونه سفارش داده بشه؟
منظورم اینه که الان محمود هم چلوکباب با دوغ را سفارش داد . آیا این سفارش ها که هم نام با سفارش های میلاد هستن ، در واقع ، یک رکورد میتونن باشن یا رکوردهای سفارشِ محمود (که چلوکباب و دوغ بود) با رکوردهای سفارش میلاد (که اون هم چلو کباب با دوغ بود) ، مجزا هست؟
اگه مجزا باشه ، رابطه شون 1 به n هه .
وگرنه رابطه شون n به n هه .
--------------
استاد ، وقتی SSMS را اجرا و جای Server Name ، مقدار نقطه (.) میذارم ، وقتی دکمه ی connect را میزنم ، بعد از فرضا 1 دقیقه تلاش برای متصل شدن ، ارور میده و میگه برای اطلاعات بیشتر ، به لینک زیر برین (عکسش را بذارم؟) :
Troubleshoot and resolve network-related or instance-specific errors when connecting to SQL Server. Follow step-by-step guidance to fix common configuration issues.
learn.microsoft.com
مطالب لینک بالا خیلی زیاده .
شما میدونین علت این ارور چیه و چی کار باید کرد؟
تشکر استاد .
ببخشید که چند پست بالا هم خیلی زیاد شد .
استاد ، وقتی SSMS را اجرا و جای Server Name ، مقدار نقطه (.) میذارم ، وقتی دکمه ی connect را میزنم ، بعد از فرضا 1 دقیقه تلاش برای متصل شدن ، ارور میده و میگه برای اطلاعات بیشتر ، به لینک زیر برین (عکسش را بذارم؟) :
Troubleshoot and resolve network-related or instance-specific errors when connecting to SQL Server. Follow step-by-step guidance to fix common configuration issues.
learn.microsoft.com
مطالب لینک بالا خیلی زیاده .
شما میدونین علت این ارور چیه و چی کار باید کرد؟
تشکر استاد .
ببخشید که چند پست بالا هم خیلی زیاد شد .
اما استاد یه سئوال .
من فکر کردم ، دیدم اغلب ارتباطات ، ارتباطات چند به چند (n به n) هست .
بعضی جاها ممکنه رابطه ی یک به یک داشته باشیم .
اما من حداقل در مسائلی که تا حالا دیدم ، رابطه ی "یک یه چند" یا همون "1 به n" ندیدم باشه (یا خیلی کمتر دیدم).
الان در پست 108 ، رابطه ی "Customers" و "Recipt" (مشتری و سفارش) ، رابطه ی چند به چند نمیشه؟
دقیق نمیدونم . به نظرم میاد که رابطه شون چند به چند بشه .
چون مشتریِ شماره ی 1 (فرضا بنام "میلاد") ، میتونه چند تا سفارش بده (یعنی 2 تا ID ئه Recipt ، متلعق به مشتری شماره 1 که میلاد بود ، باشه) . مثلا میلاد ، سفارش چلوکباب با دوغ را میده .
اما آیا این 2 تا ID ئه سفارش مشتری (که نام غذاهاشون چلوکباب با دوغ بودن) ، توسط مشتریِ شماره ی 2 (که فرضا اسمش "محمود" هست) هم میتونه سفارش داده بشه؟
منظورم اینه که الان محمود هم چلوکباب با دوغ را سفارش داد . آیا این سفارش ها که هم نام با سفارش های میلاد هستن ، در واقع ، یک رکورد میتونن باشن یا رکوردهای سفارشِ محمود (که چلوکباب و دوغ بود) با رکوردهای سفارش میلاد (که اون هم چلو کباب با دوغ بود) ، مجزا هست؟
اگه مجزا باشه ، رابطه شون 1 به n هه .
وگرنه رابطه شون n به n هه .
تشکر استاد .
ببخشید که چند پست بالا هم خیلی زیاد شد .
سلامی مجدد استاد .
در پست 108 ، اگه اشتباه نکنم ، ارتباط جدول های "Customers" و "Recipt" ، ارتباط یک به چند هست . چون هر مشتری ، میتونه چند سفارش را بده که مختص خودش هست و اون سفارش ، زمان خاصی داره که نمیتونه به مشتریِ دیگه ای (بصورت مشترک) تعلق بگیره .
همچنین ارتباط جداول "Customer" با "Food" ، ارتباطی چند به چند هست . چون هر سفارش میتونه شامل چندین غذا بشه و هر غذا هم میتونه توسط چندین سفارش (های مختلف) ، سفارش داده شده باشه .
پس چون بینِ دو جدولِ "Customer" با "Food" ، رابطه ی n به n هست ، برای ارتباط این دو جدول ، بهتره یه جدول مجزای دیگه (جدول فصل مشترک) طراحی کنیم که کلید خارجیِ مربوط به هر دوی این جداول ، درونِ اون جدولِ فصل مشترک قرار داده بشه .
سلامی مجدد استاد .
استاد ، مطالب زیر را بی زحمت درستی یا نادرستی اش را چک میکنید؟
در پست 120 ، عکس اولی (عکس بالا) ، همونطور که اگه مدل سازیِ شی گرا ئه جداول بالا را انجام بدیم ، به این صورت میشه که یه کلاس "مشتریان" تعریف میکنیم و یه enum هم به عنوان "گروه مشتریان" تعریف میکنیم (تا این enum ، اعضایی به عنوان "مشتری vip" و "مشتری حضوری" و "مشتری تلفنی" و ... داشته باشه) ، و عضوی از نوع این enum را درون کلاس "مشتریان" قرار میدیم و همونطور هم که قبلا گفته شد ، در مدل سازی ، هر نوعی از کلاس و enum ، در طراحی دیتابیس ، یه جدول و موجودیتی مجزا میشن ، پس ، عکس بالا (عکس اول در پست 120) درست هست و "گروه مشتریان" ، درون جدولی مجزا قرار داده میشه .
همچنین اگه از منظر طراحی دیتابیس هم بخوایم ببینیم (یعنی از منظر مدل سازی شی گراش نبینیم) ، ممکنه کاربر نهایی بخواد یه "گروه مشتریان" ئه جدیدی ایجاد کنه یا یکی از گروه های موجود را حذف کنه که ربطی به خودِ مشتریان نداره ، پس "گروه مشتریان" باید در جدولی مجزا قرار داده بشه .
و همچنین برای جدول های "کاربران" و "گروه کاربران" هم همینطوره .
اما نکته ی مهم اینجاست که رابطه ی جدول های "مشتریان" و "گروه مشتریان" ، رابطه ای چند به چند هست . چون هر رکورد و هر مشتری ، میتونه همزمان ، عضو چند گروهِ مشتریان باشه (فرضا هم از نوع مشتری تلفنی و هم از نوع مشتری vip باشه) و علاوه بر این ، هر "گروه مشتزیان" هم همزمان میتونه به چندین رکورد از مشتری ، تعلق داشته باشه .
بنابراین چون رابطه شون چند به چند میشه ، بهتر بود (یا باید) ، یه جدول فصل مشترک براشون میساخت و کلید های خارجیِ مربوط به این دو جدول را درون اون جدول فصل مشترک قرار میداد .
در این عکس (عکس دوم در پست 120) هم جدول "گروه غذا" به همون دلیل بهتره که در جدول مجزایی باشه (که هست) اما نکته اینکه رابطه ی بین این دو جدول ، رابطه ی یک به چند هست . چون یک گروه از غذا (فرضا گروهِ "نوشیدنی") ، میتونه به چند غذا (مثل دوغ و نوشابه) تعلق بگیره .
چون در اینجا اون طرفی که جدول "غذا" هست ، رابطه ی n داره ، طبق چیزی که در چند پست قبل درباره ی روابط گفته شد ، پس ستونی به عنوان کلید خارجی باید درون جدول "غذا" قرار بگیره که کلید اصلیِ جدول "گروه غذا" ، بهش اشاره کنه (حالا نمیدونم ستون "دسته بندی" در این جدول ، کلید خارجی ای از همین کارکرد هست یا نه ، وگرنه ستونی با این کارکرد در این جدول انگار پیدا نمیشه) .
جدول "واحدها" ، نمیدونم دقیقا چیه و کارکردش چیه .
اما هر چی روی جدول "موجودی" فکر میکنم ، اصلا نمیتونم دلیلی پیدا کنم که به عنوان یه موجودیت و جدولی مجزا مطرح بشه!! آخه چه دلیلی میتونه داشته باشه؟!!
موجودی برای هر غذا ، کافی هه به عنوان ستونی در جدول غذا ، تعریف بشه .
"موجودی غذا" ، در مدل سازی شی گرا ، نه به عنوان یه کلاس و نه به عنوان یه enum میشه مطرح کرد تا به عنوان موجودیتی مجزا ، درون جدولی مجزا مطرح بشه . همچنین نه داده ای هست که اتمیک نباشه (تجزیه ناپذیر هست) و چندین صفت هم نداره و همچنین نه رابطه اش با جدول "غذا" ، یک به چند ، یا چند به چند نیست (همیشه یک به یک هست) .
یا چیزی هست که من نمیدونم ، یا چیزی به این راحتی را نمیدونم چرا در جدولی مجزا ایجاد کرد!!
موجودیتِ "فاکتور" هم چندین صفتِ مخصوص خودش مثل تاریخ و ساعت و قیمت کل و ... داره پس در جدولی مجزا تدارک دیده میشه .
ستون "کد کاربر" اش که هیچ (بحثی در این باره ندارم و کلید خارجی هست و درسته) .
اما برای ارتباط با بقیه ی جداول ، فقط ستون "کد مشتری" اش (به عنوان کلید خارجی) کافی بود دیگه . یعنی با وجود این ستون ، دیگه نیازی به ستون های "کد سفارش" و "کد غذا" نیست . چون جدول "مشتری" ، با جدول "سفارش مشتری" ، و جدول "سفارش مشتری" هم با جدول "غذا" ارتباط داره . بنابراین ارتباط این جدول هم بصورت غیر مستقیم با اون جداول ، حتی بدون وجود این ستون ها هم برقرار میشه (با استفاده از چندین inner join) و نیاز به قرار دادن این ستون ها در این جدول نیست .
این قضیه را (ارتباط غیر مستقیم) ، در همون فیلم آموزشی که در پست 123 اشاره کردم ، گفت . که واقعا آموزش خوبی بود .
من خودم در طراحی دیتابیس ضعیفم ، اگه این آموزش که در این پست به نظرم ایراداتش را گفتم ، اشکال داشته باشه ، آدم رو گمراه میکنه .
سلامی مجدد
استاد ، این نکته را هم در خلال ادامه ی مباحث دیتابیس یاد گرفتم . (درستی اش را دقیق نمیدونم و اگه میشه بی زحمت چک کنین اما فکر کنم به احتمال بسیار زیاد ، درست باشه) :
اگر رابطه ی بین دو موجودیت (جدول) ، چند به چند باشه ، موجودیتِ (جدولِ) دیگه ای به عنوان موجودیتِ (جدولِ) فصل مشترک براشون در نظر میگیریم که این جدول ، هم حاوی کلیدهای خارجیِ مربوط به هر دو جدول دیگه هست و هم حاوی صفت هایی که بین این دو جدول ، مشترک باشه .
مثلا در جدول های دانشجو و درس ، چون رابطه ی چند به چند بین این دو جدول هست ، پس جدول دیگه ای به عنوان جدول فصل مشترک براشون در نظر میگیریم (فرضا جدولی بنام "جدول مشترک") که حاوی هم صفت هایی (یا همون ستون هایی) به عنوان کلید خارجی از هر دو جدول مربوط به دانشجو و درس ، درون این جدولِ "جدول مشترک" هست (یعنی کلیدهای خارجی مربوط به کلید اصلی جدول های دانشجو و درس ، درون "جدول مشترک" تعریف میشه . یعنی صفاتِ کلیدهای خارجی ای مثل FK_StudentID و FK_LessonID ، درون "جدول مشترک" تعریف میشن) و همچنین صفاتی که مربوط به هر دو جدولِ دانشجو و درس هستند هم درون "جدول مشترک" تعریف میشن . صفتی مثل "نمره" که هم مربوط به درس هست و هم مربوط به دانشجو هست ، درون "جدول مشترک" تعریف میشه .
چون نمره ، صرفا مربوط به درس نیست . چون اگه فقط مربوط به درس بود ، پس برای کدوم دانشجو هست؟
و همچنین نمره ، صرفا مربوط به دانشجو نیست . چون اگه این طور بود ، مربوط به کدوم درسِ دانشجو هست؟
بنابراین صفاتی مثل نمره ، زمان و مکان برگزاری امتحان و ... که مربوط به هر دو جدول دانشجو و درس هست ، درون "جدول مشترک" نوشته میشن .
حتی ممکنه که بعضی از این صفات ، باز بصورت مشترک با جدول استاد هم مشترک باشن که باز در جدولی مجزا نوشته میشن (در صورتی که رابطه ی چند به چند باشه) (البته بستگی به نیازمندی ها و طراحی هم داره) .
رابطه ، میتونه بین چندین موجودیت بصورت مستقیم وجود داشته باشه (یعنی این طور نیست که الزاما ، یک رابطه ، فقط بین دو موجودیت وجود داشته باشه ؛ بلکه یک رابطه ، بصورت مستقیم میتونه بین 3 تا موجودیت برقرار باشه) .
در این صورت ، اگه روابط بین شون ، چند به چند بود ، باید کلید اصلی همه ی جداول دیگه (ای که رابطه ی چند به چند دارند) ، به عنوان کلید خارجی ، در جدولی که رابطه را مشخص میکنه ، تعیین میشه .
مثلا اگه 3 جدول بصورت مستقیم رابطه داشتند ، جوری که ارتباط بین همه شون ، چند به چند بود ، باید کلید اصلی هر 3 جدول ، درون جدولی که رابطه را تشکیل میده ، به عنوان کلید خارجی ، قرار بگیره .
و این ، به این معناست که برای ارتباط برقرار کردن ، باید اطلاعات هر 3 جدول (در یک رکورد) ، وجود داشته باشه .
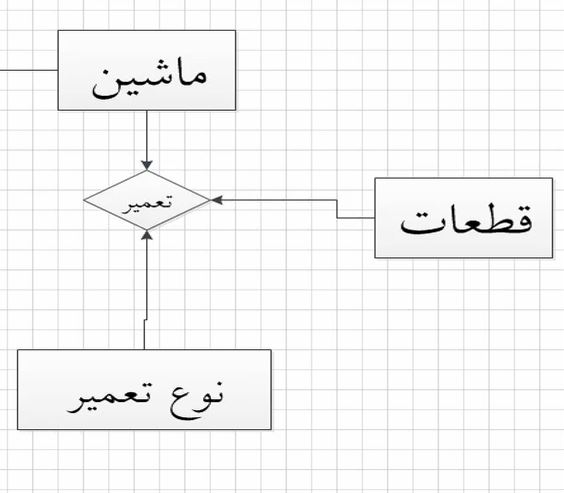
مثل شکل زیر :
که در این عکس (اگه تبدیل به جدول بشه) ، همزمان باید کلیدهای 3 جدولِ "ماشین" و "نوع تعمیر" و "قطعات" ، (در صورت وجود رابطه ی چند به چند بین این جداول) ، به عنوان کلید خارجی ، در جدول "تعمیر" قرار بگیره . (در نمودار ER ، اون "تعمیر" رابطه هست که در دیتابیس ، بخاطر روابط چند به چند بین همه ی این موجودیت ها ، خود "تعمیر" ، به یه جدول مجزا تبدیل میشه) .
یعنی برای اینکه در جدول "تعمیر" ، رکوردی ثبت کنیم ، باید هم اطلاعات "ماشین" ، و هم "نوع تعمیر" و هم "قطعات" ، با هم و یکجا (در اون رکورد) وجود داشته باشه و در اون رکورد قرار بدیم .
ارتباط "تعمیر" در شکل بالا ، درجه 3 هست . یعنی با 3 تا جدول ، بصورت مستقیم ، ارتباط داره .
===============
موجودیت یا جدول را زمانی مینویسیم که میخوایم درباره ی اون چیز ، اطلاعاتی ثبت کنیم . همچنین موجودیت ها ، شامل صفت هایی هستند (معمولا شامل چند صفت هستند) .
قضیه ی شی گرایی و مدل سازی برای ساختن موجودیت هم استفاده میکنیم . یعنی در شی گرایی ، هر جا کلاسی ایجاد کردیم ، یا کلاسی که از کلاس دیگه ای ارث بری میکنه ، ساختیم یا enum ساختیم ، در این صورت ، به ازای هر یک از اینها ، در مدل سازی برای دیتابیس ، یک موجودیت و در واقع ، یک جدول میسازیم .
سلامی مجدد استاد .
ادامه ی پست قبلی (بی زحمت ، مطالب زیر را برای درست بودنش ، چک میکنید) :
ارتباطات جداول در sql :
ارتباطات جداول در sql ، سه نوع هستن :
1- ارتباطات یک به یک :
وقتی به ازای هر سطر از یک جدول ، نیاز باشه که داده ای را فقط یه سطر از یه جدول دیگه ذخیره کنیم (یا کلا باهاش ارتباط برقرار کنیم) ، به این ارتباط ، ارتباط یک به یک در دو جدول میگن .
در این ارتباط ، داده هایی که در هر رکورد از ستون (صفت) از هر دو جدول قرار میگیره ، به هیچ عنوان نباید مشترک باشن (و فقط باید منحصر به فرد باشن) وگرنه نوع ارتباط شون ، "یک به n" یا "n به n" میشه .
رابطه ی جدول (در واقع موجودیت) "استاد" و جدول "درس" در دو عکسِ بالا ، زمانی "رابطه ی یک به یک" هست که فقط به ازای هر رکورد از استاد ، یک رکورد از درس (که هر دوشون نباید مشترک باشن) ، ثبت بشه .
- دوما ، نکته ی مهم در این نوع ارتباطِ یک به یک ، اینه که کلید خارجی را در کدوم یک از این جدول ها بذاریم (در واقع تعیین اینکه کدوم جدول ، جدول فرزند بشه) :
اطمینان 100 درصد ندارم اما تا جایی که تا حالا متوجه شدم ، اول باید ببینیم جدول اصلی مون کدوم هست . جدول اصلی مون هم احتمالا اون جدولی میشه که میخوایم بر پایه ی اون ، جستجو انجام بدیم .
یعنی فرضا اگه در اینجا بخوایم بر اساس نام (یا id و کلا بر اساس جدولِ) استاد ، جستجو مون را انجام بدیم ، پس جدول "استاد" ، جدول اصلی مون یا همون جدول والد مون میشه . بنابراین جدول مقابل ، یعنی جدول درس ، جدول فرزندمون میشه و چون جدول فرزند هم جدولی هست که ستون (صفت) با کلید خارجی درون اون جدول تعریف میشه ، پس اگه در شکل بالا ، بخوایم بر اساس جدول "استاد" جستجو کنیم (که در این صورت ، این جدول ، جدول والدمون میشه) ، پس کلید خارجیِ این جدول را درون جدول "درس" قرار میدیم .
یعنی مثل عکس بالا ، یه ستون (یا صفت ای) فرضا بنام "ProfessorID" یا بنام "MasterID" (فیلد قرمز در عکس دوم در بالا) را درون جدول درس قرار میدیم که این ستون ، به ستونِ ID در جدول "استاد" اشاره کنه و این ستون (قرمز رنگ) ، کلید خارجی هم هست .
- یا اینکه اگه میخوایم بدونیم که ستون (صفتی) که کلید خارجی داره را درون کدوم جدول قرار بدیم ، توسط مدل سازیِ شی گرا اش عمل میکنیم .
در این مدل سازی ، یک کلاس "استاد" و یک کلاس "درس" میسازیم . چون کلاس استاد ، عضوی از نوع کلاس "درس" را توی خودش داره(و این عضو در کلاس استاد ، به شی ای از کلاس "درس" اشاره میکنه) ، پس در مدل سازیِ دیتابیس اش هم همونطور که در بالا توضیح دادیم میشه . یعنی ستون "MasterID" ، به عنوان کلید خارجی ، در جدول "درس" قرار میگیره تا مثل مدل سازیِ شی گرا اش ، ستونِ ID در جدول "استاد" ، به ستون "MasterID" در جدول "درس" که کلید خارجی هست ، اشاره کنه (کلید اصلی هم که همیشه به کلید خارجی اشاره میکنه . البته در صورت وجود داشتن کلید خارجی در یک جدول دیگه) .
و کدش هم بصورت زیر میشه :
SQL:
SELECT Name, Family, Title
FROM tblMaster inner join tblLesson
ON tblMaster.ID = tblLesson.MasterID
- و اگه برعکس اش را بخوایم ، یعنی بخوایم طبق جدول "درس" ، جستجومون را انجام بدیم ، در این صورت ، ستونی به عنوان کلید خارجی ای در جدول "استاد" میذاریم که ID ئه جدول "درس" ، بهش اشاره کنه .
و البته شاید بشه که در هر دو جدول ، کلید خارجیِ جدول دیگه را قرار بدیم (نمیدونم) .
سلامی مجدد
استاد ، البته از این دید هم میشه نگاه کرد که در رابطه ی یک به یک ، ببینیم که چه اطلاعاتی میخوایم .
مثلا وقتی در جدول "استاد" جستجو میکنیم (عکس دوم در پست 124) ، میخوایم بدونیم که این استاد ، چه درسی را گرفته (پس ، ID ئه جدول "درس" را _به عنوان ستون کلید خارجی_ درون جدول "استاد" تعریف میکنیم ؛ یعنی جدول استاد ، در اینجا ، جدول فرزند میشه) و اگه بخوایم وقتی در جدول درس جستجو میکنیم ، بدونیم که این درس ، مدرس اش کدوم استاد هست ، ID ئه جدول "استاد" را به عنوان کلید خارجی ، درون جدول "درس" میذاریم .
البته باز هم شاید چندان فرقی نکنه چون در هر دو حالت (چه اینی که در این پست گفتم و چه در پست 124) فرق چندان خاصی با هم فکر نکنم داشته باشن (دقیق نمیدونم) چون در هر دو حالت ، برای ارتباط شون باید inner join بزنیم که سطر های مشترک از دو جدول را انتخاب میکنه و در نتیجه فرق خاصی (حداقل در وهله ی اول) نداره .
-----------
***البته یکی از آموزش ها ، همین نکته ی بالا را به این صورت گفت که جدول ضعیف ، به جدولی میگن که در یک رابطه ، لازم نباشه تا تمام سطرهاش ، با جدول دیگه ، ارتباط داشته باشه اما جدول قوی ، به جدولی میگن که تمام سطرهاش ملزم هست که در اون رابطه ، شرکت کنه .
و این طور گفت که در رابطه ی یک به یک ، ID ئه جدول ضعیف ، درون جدول قوی قرار میگیره . یعنی کلید خارجی در جدول قوی قرار میگیره و ID ئه جدول ضعیف ، بهش اشاره میکنه . یعنی جدول قوی (چون کلید خارجی توش تعریف شد) ، به عنوان جدول فرزند محسوب میشه .
البته نمیدونم واقعا گفته اش درست هست یا نه .
==========
*** یه نکتهدرباره ی شکل پست قبل (پست 130) ، اینکه مشخص هست که فرضا اگه میخوایم جدول "قطعات" ، لازم نباشه که در اون ارتباط بصورت مستقیم شرکت کنه (یعنی لازم نباشه که همزمان ، اطلاعات 3 جدول "قطعات" و "نوع تعمیر" و "ماشین" ، همه یکجا و با هم ثبت بشن) ، در این صورت ، جدول "قطعات" میتونه در ارتباطی مجزا با جدول "تعمیر" ، ارتباط داشته باشه .
ارتباط "تعمیر" در جدول بالا ، بخاطر اینکه ، حداقل بین جدول "ماشین" و "نوع تعمیر" ، در ارتباطِ "تعمیر" ، رابطه ای چند به چند هست ، پس این ارتباط ، به یک جدول مجزا تبدیل میشه (واسه ی همین در بالا ، به عنوان جدول "تعمیر" بهش اشاره کردم) .
سلامی مجدد
استاد ، اگه صفت های یک جدول ، رابطه ی یک به چند داشتن ، میدونیم که اون صفتی که چند تاست را باید در جدولی مجزا طراحی کنیم .
مثلا وقتی برای یک فرد ، شماره تلفنی در نظر میگیریم که چند تا میتونه شماره تلفن داشته باشه ، در اینجا نباید در یک جدول ، ستونی بنام "نام" و "شماره تلفن" داشته باشیم .
بلکه ستون "شماره تلفن" را در جدولی مجزا باید طراحی کنیم (و کلید خارجی را درون این جدول قرار بدیم که این موضوع را میدونستم) .
--------
اما سئوالم اینجاست که معکوسِ این حالت هم نیاز به طراحی جدولی مجزا داره؟
یعنی مثلا اگه رابطه چند به یک باشه ، نیاز به طراحی اون ستون ، درون جدولی مجزا داره؟ یا اینکه درون همون جدول هم میتونیم به عنوان یه صفت در نظرش بگیریم؟
مثلا فرض کنید توی همون قضیه ی غذا ، میتونیم وقتی یه جدولی بنام "غذا" داریم و ستونی بنام "نام غذا" داره، آیا میتونیم درون همین جدول ، یه ستونی هم بنام "گروه غذا" داشته باشیم ، یا بهتره که ستون "گروه غذا" را به عنوان جدولی مجزا طراحی کنیم؟
چون نام "غذا" با "گروه غذا" ، رابطه ای برعکسِ حالت قبلی ، یعنی چند به یک دارند (البته به نوعی همون یک به چند هست) .
در واقع هر یک گروه غذا ، میتونه شامل یک یا چند غذا بشه .
یعنی اگه مثلا هر دوشون به عنوان ستونی درون یک جدول باشن (یا حتی بصورت جدولی مجزا باشن) ، به ازای فرضا غذایی بنام دوغ ، گروه نوشیدنی و همچنین به ازای غذایی بنام نوشابه ، گروه نوشیدنی خواهیم داشت .
سئوالم اینه که آیا اصول طراحی پایگاه داده نقض میشه که در این نوع رابطه (در رابطه ی چند به یک) ، هر دو ، به عنوان صفتی درون یک جدول طراحی بشن یا اینکه باید درون جدول های مجزا قرار بگیرن؟
ببخشید استاد ، این سئوال را جواب میدین (دونستن اش برام تقریبا مهم هست) .
تشکر استاد .
ساختن و ایجاد ارتباطات در کلاس های Business Logic ، بر حسب ارتباطات و چهارچوب و قوانین Composition یا Aggregation یا Association هست که در فایل Visual Studio C#.docx توضیح داده شد .
اما ساختن و ایجاد ارتباطات در Entity Framework ، فقط بر اساس روابط "یک به یک" یا "یک به چند" یا "چند به چند" هست که همان ،چهارچوب روابط در زمان ساخت دیتابیس و جدول ها هستند .
این طور نیست که این روابطِ "یک به یک" یا "یک به چند" یا "چند به چند" ، بر اساس حتی چهارچوب Association تعریف بشوند .
بلکه چطور روابط را در دیتابیس و جدول ها برقرار میکنیم که این چهارچوب بر اساس "یک به یک" یا "یک به چند" یا "چند به چند" هستند ، همانطور هم این چهارچوب را برای ایجاد روابط در Entity Framework اعمال میکنیم .
اما مکان کلاسی که پروپرتی های Navigation برای ایجاد ارتباطات در کلاس های Entity در Entity Framework در آن قرار میگیرند ، دقیقا برعکسِ جدولی هست که کلیدخارجی در آن جدول قرار میگیرد .
یعنی معنای کلید خارجی این هست که اشاره گری ، به آن ، از جای دیگر ، اشاره میکند . یعنی به کلید خارجی ، اشاره میشود . مثلا وقتی در دیتابیس ، دو جدولِ Student و StudentAddress داریم که در جدول StudentAddress ، کلید خارجی ای قرار دارد ، به این معناست که کلید اصلی جدول Student ، دارد به کلید خارجیِ جدول StudentAddress اشاره میکند . در واقع ، کلید خارجیِ جدولِ StudentAddress ، دارد از جدول دیگر اشاره میشود .
برخلاف پروپرتی های Navigation که اشاره میکنند و اشاره گر هستند (اما به کلید خارجی ، اشاره میشود) ، پس پروپرتی های Navigation ، در کلاسِ مقابلِ جدولی که کلید خارجی در آن قرار دارد ، قرار میگیرند .
هر چند در EF ، پروپرتی های Navigation ، در هر دو طرف از کلاس ها ، قرار میگیرند .
نحوه ی ساخت الگوی جنریک Repository به همراه الگوی Unit Of Work با استفاده از کلاس های DbContext و DbSet های Entity Framework :
یک interface برای هر یک از موجودیتهای دامنه خود تعریف کنید که عملیات مورد نظر شما را برای دسترسی به دادهها در بر دارد. به عنوان مثال، برای موجودیت Product میتوانید یک interface با نام IProductRepository تعریف کنید که شامل توابعی مانند GetAllProducts، GetProductById، AddProduct و … باشد.
سپس، یک کلاس پیادهسازی برای هر یک از این interface ها تعریف کنید که از DbContext و DbSet های آن برای دسترسی به دادهها استفاده میکند. به عنوان مثال، برای interface IProductRepository میتوانید یک کلاس با نام ProductRepository تعریف کنید که از DbContext شما برای دسترسی به DbSet<Product> استفاده میکند.
در لایه Business Logic خود، به جای استفاده مستقیم از DbContext و DbSet ها، از این Repository ها استفاده کنید.
به این ترتیب، شما یک لایه Repository را با استفاده از DbContext و DbSet های Entity Framework پیادهسازی کردهاید.
یک مثال ساده از پیادهسازی الگوی جنریک Repository و همچنین الگوی Unit Of Work (همان پیاده سازی متد Save) با استفاده از DbContext و DbSet های Entity Framework :
C#:
public interface IRepository<T> where T : class
{
IEnumerable<T> GetAll();
T GetById(int id);
void Add(T entity);
void Save();
}
public class Repository<T> : IRepository<T> where T : class
{
private readonly MyDbContext _context;
private readonly DbSet<T> _dbSet;
public Repository(MyDbContext context)
{
_context = context;
_dbSet = context.Set<T>();
}
public IEnumerable<T> GetAll()
{
return _dbSet.ToList();
}
public T GetById(int id)
{
return _dbSet.Find(id);
}
public void Add(T entity)
{
_dbSet.Add(entity);
}
public void Save()
{
_context.SaveChanges();
}
}
در مثال بالا ، یک interface به نام IRepository<T> تعریف شده است که شامل توابع GetAll، GetById و Add میشود. سپس، یک کلاس به نام Repository<T> تعریف شده است که این interface را پیادهسازی میکند و از DbContext برای دسترسی به DbSet<T> استفاده میکند.
در مثال بالا ، متد SaveChanges() را درون بدنه متد Add فراخوانی نکردم تا اجازه داشته باشیم که تغییرات را به صورت دستهای (batch) در پایگاه داده ذخیره کنیم. به این ترتیب، میتوانیم چندین تغییر را اعمال کنیم و سپس با فراخوانی متد Save، همه آنها را به صورت همزمان در پایگاه داده ذخیره کنیم.
اما اگر شما میخواهیم تغییرات را به صورت فوری در پایگاه داده ذخیره کنیم، میتوانیم متد SaveChanges() را درون بدنه متد Add فراخوانی کنید.
================================
الگوی Unit Of Work :
یک الگوی طراحی نرمافزار است که برای مدیریت تغییرات در دادهها و اطمینان از هماهنگی بین چندین Repository استفاده میشود. این الگو به شما اجازه میدهد تا تغییرات را در حافظه جمعآوری کنید و سپس همه آنها را با یک تراکنش دادهای به پایگاه داده اعمال کنید. این کار باعث میشود که تغییرات شما به صورت همزمان و هماهنگ اعمال شوند و در صورت بروز خطایی، همه تغییرات بازگردانده شوند.
فرض کنید شما یک برنامه دارید که اطلاعات سفارشات را در پایگاه داده ذخیره میکند. هر سفارش شامل چندین محصول است و هر محصول نیز قیمت خود را دارد. حال فرض کنید که شما میخواهید قیمت یکی از محصولات را تغییر دهید و همچنین مجموع قیمت سفارشاتی که این محصول را دارند را بهروزرسانی کنید.
بدون استفاده از الگوی Unit Of Work، شما باید تغییر قیمت محصول را در پایگاه داده ذخیره کنید و سپس به صورت جداگانه برای هر سفارش، مجموع قیمت آن را بهروزرسانی کنید. این کار باعث میشود که در صورت بروز خطایی در هنگام بهروزرسانی یکی از سفارشات، بقیه تغییرات نیز نامعتبر شوند.
با استفاده از الگوی Unit Of Work، شما میتوانید تغییرات را در حافظه جمعآوری کنید و سپس همه آنها را با یک تراکنش دادهای به پایگاه داده اعمال کنید. این باعث میشود که تغییرات شما به صورت همزمان و هماهنگ اعмال شوند و در صورت بروز خطایی، همه تغیرات بازگردانده شوند.
این الگوی Unit Of Work ، توسط متد Save در کد شماره ی 6 که الگوی جنریک Repository را هم پیاده سازی کرده بود ، پیاده سازی شد (کار خاص دیگه ای نداره) .
انتقال اطلاعات رکوردهای جدول و حذف نشدن آنها در مدل جدول و Entity جدید :
در Entity Framework Code First ، برای اینکه Entity Framework اتوماتیک پایگاه داده را ایجاد کند ، یا کلاس های Entity و مدل ای که ساخته شدند را تغییر دهد آن هم بدون اینکه داده ها و رکوردهایی که از قبل در پایگاه داده وجود دارند ، حذف نشوند ، 2 راهکار ارائه کرد . اولی اینکه از Data Migration و دومی اینکه از متد Seed در کلاس های DropCreateDatabaseIfModelChanges<TContext> یا کلاس DropCreateDatabaseAlways<TContext> استفاده کنیم برای اینکه رکورد و داده و اطلاعاتی که در دیتابیس مان از قبل وجود دارد و حذف نشود تا این اطلاعات در پایگاه داده را نگه داریم .
متد Seed برای این است که قبل از حذف پایگاه داده ، اطلاعات و رکوردهای آن را درون حافظه استخراج کرده و سپس در جدول جدیدی که Entity Framework ایجاد میکند ، مجدداً ذخیره کنیم .
یعنی متد Seed ای که اشاره کردم برای این هست تا فرضا اگر از متد DropCreateDatabaseIfModelChanges<TContext>.Seed استفاده کردیم ، در ابتدا در بدنه ی این متد ، قبل از اینکه پایگاه داده مان حذف شود ، اطلاعات و رکوردها را از آن در حافظه ی متغییرمان استخراج و بعد ، داخل جدول جدیدی که Entity Framework ایجاد میکند ، مجددا این اطلاعات جدید را در جدول جدید ، ذخیره کنیم .
مثال ساده :
C#:
// تعریف کلاس DbContext برای پایگاه داده قبلی
public class OldDbContext : DbContext
{
public DbSet<MyEntity> MyEntities { get; set; }
// تنظیمات اتصال به پایگاه داده قبلی
protected override void OnConfiguring(DbContextOptionsBuilder optionsBuilder)
{
optionsBuilder.UseSqlServer("connectionStringForOldDatabase");
}
}
// تعریف کلاس DbContext برای پایگاه داده جدید
public class NewDbContext : DbContext
{
public DbSet<MyEntity> MyEntities { get; set; }
// تنظیمات اتصال به پایگاه داده جدید
protected override void OnConfiguring(DbContextOptionsBuilder optionsBuilder)
{
optionsBuilder.UseSqlServer("connectionStringForNewDatabase");
}
}
// بازیابی دادهها از پایگاه داده قبلی و ذخیره آنها در پایگاه داده جدید
using (var oldDbContext = new OldDbContext())
using (var newDbContext = new NewDbContext())
{
// بازیابی دادهها از پایگاه داده قبلی
var oldData = oldDbContext.MyEntities.ToList();
// ذخیره دادهها در پایگاه داده جدید
newDbContext.MyEntities.AddRange(oldData);
newDbContext.SaveChanges();
}
خطای زیر در EF6 Code First :
"no connection string named 'Name' could be found in the application config file"
و همچنین خطای :
"no entity framework provider found for the ado.net"
خطاهای بالا ، هر چند یعنی تگِ Connection String ، را در فایل App.config را پیدا نکرد ، اما مفهوم و علتی جداگانه از این هم میتونه داشته باشه .
علت مهم پیام دوم (و حتی اول) اینه که اگر برنامه را بصورت لایه ای ، و هر لایه را در یک پروژه مینویسیم ، حتما برای اینکه EF درست کار کنه ، باید علاوه بر اینکه پکیج EF6 را که درون هر پروژه ای (مثلا پروژه و لایه ی DataAccess) نصب کردیم ، علاوه بر اون ، این پکیجِ EF6 را هم درون لایه و در واقع درون پروژه ای که در startup اجرا میشود (معمولا پروژه ای که View مان را شامل میشود) هم باید نصب کنیم .
در واقع این کار ، باعث رفع خطای پیغام دوم میشود .
حتی بعد از انجام این کار ، هنوز خطای اول را داریم و باید در فایل App.config ای که درون پروژه ای که بصورت startup هم اجرا میشود (معمولا پروژه ی View) ، باید تگِ مربوط به Connection String ای که درون فایلی با همین نام (App.config) ای که درون پروژه ی DataAccess قرار داردرا به همین فایلِ App.config ای که درون پروژه ی View مان قرار دارد (پروژه ای که بصورت startup project اجرا میشود) ، کپی کنیم .
مثلا عبارت زیر را کپی کنیم :
برای متصل شدن به پایگاه داده ای که در مثال بالا آورده شده ، در برنامه ی Sql Server Management Studio (یا همان SSMS) ، در پنجره ی Connect To Server و در TextBox ای بنام Server Name ، کل مقدارِ "data source" در کد بالا را که همان مقدارِ (LocalDb)\MSSQLLocalDB هست را درون این TextBox قرار دهید و دکمه ی connect را در پنجره کلیک کنید .
سلامی مجدد
استاد ، این نکته را هم در خلال ادامه ی مباحث دیتابیس یاد گرفتم . (درستی اش را دقیق نمیدونم و اگه میشه بی زحمت چک کنین اما فکر کنم به احتمال بسیار زیاد ، درست باشه) :
اگر رابطه ی بین دو موجودیت (جدول) ، چند به چند باشه ، موجودیتِ (جدولِ) دیگه ای به عنوان موجودیتِ (جدولِ) فصل مشترک براشون در نظر میگیریم که این جدول ، هم حاوی کلیدهای خارجیِ مربوط به هر دو جدول دیگه هست و هم حاوی صفت هایی که بین این دو جدول ، مشترک باشه .
مثلا در جدول های دانشجو و درس ، چون رابطه ی چند به چند بین این دو جدول هست ، پس جدول دیگه ای به عنوان جدول فصل مشترک براشون در نظر میگیریم (فرضا جدولی بنام "جدول مشترک") که حاوی هم صفت هایی (یا همون ستون هایی) به عنوان کلید خارجی از هر دو جدول مربوط به دانشجو و درس ، درون این جدولِ "جدول مشترک" هست (یعنی کلیدهای خارجی مربوط به کلید اصلی جدول های دانشجو و درس ، درون "جدول مشترک" تعریف میشه . یعنی صفاتِ کلیدهای خارجی ای مثل FK_StudentID و FK_LessonID ، درون "جدول مشترک" تعریف میشن) و همچنین صفاتی که مربوط به هر دو جدولِ دانشجو و درس هستند هم درون "جدول مشترک" تعریف میشن . صفتی مثل "نمره" که هم مربوط به درس هست و هم مربوط به دانشجو هست ، درون "جدول مشترک" تعریف میشه .
چون نمره ، صرفا مربوط به درس نیست . چون اگه فقط مربوط به درس بود ، پس برای کدوم دانشجو هست؟
و همچنین نمره ، صرفا مربوط به دانشجو نیست . چون اگه این طور بود ، مربوط به کدوم درسِ دانشجو هست؟
بنابراین صفاتی مثل نمره ، زمان و مکان برگزاری امتحان و ... که مربوط به هر دو جدول دانشجو و درس هست ، درون "جدول مشترک" نوشته میشن .
حتی ممکنه که بعضی از این صفات ، باز بصورت مشترک با جدول استاد هم مشترک باشن که باز در جدولی مجزا نوشته میشن (در صورتی که رابطه ی چند به چند باشه) (البته بستگی به نیازمندی ها و طراحی هم داره) .
توضیح پست بالا که نقل قول کردم (درباره ی صفت هایی که باید درون جدول مشترک تعریف بشن) اشکال داره و توضیح درست و کامل ترش را در زیر میذارم :
اگر رابطه ی بین دو موجودیت (جدول) ، چند به چند باشه ، موجودیتِ (جدولِ) دیگه ای به عنوان موجودیتِ (جدولِ) فصل مشترک براشون در نظر میگیریم که این جدول ، هم حاوی کلیدهای خارجیِ مربوط به هر دو جدولِ دیگه هست (و این دو کلید خارجی درون این جدولِ فصل مشترک ، هر دوی این کلیدهای خارجی با هم ، به عنوان کلید اصلی هم در نظر گرفته میشوند ، یعنی جدول فصل مشترک ، کلید اصلی مستقل ای ندارد ، یا اینکه معمولا ندارد) و هم حاوی صفت هایی که بین این دو جدول ، مشترک باشه .
مثلا در جدول های دانشجو و درس ، چون رابطه ی چند به چند بین این دو جدول هست ، پس جدول دیگه ای به عنوان جدول فصل مشترک براشون در نظر میگیریم (فرضا جدولی بنام "جدول مشترک") که حاوی هم صفت هایی (یا همون ستون هایی) به عنوان کلید خارجی از هر دو جدول مربوط به دانشجو و درس ، درون این جدولِ "جدول مشترک" هست (یعنی کلیدهای خارجی مربوط به کلید اصلی جدول های دانشجو و درس ، درون "جدول مشترک" تعریف میشه و با هم ، به عنوان کلید اصلی ، در نظر گرفته میشوند . یعنی صفاتِ کلیدهای خارجی ای مثل FK_StudentID و FK_LessonID ، درون "جدول مشترک" تعریف میشن و هر دو با هم ، به عنوان کلید اصلیِ این جدول تعریف میشوند) و همچنین صفاتی در یک جدول را که مالِ (متعلق به) یک رکوردِ خاص در جدولِ دیگر هست (یعنی مالکیتِ یک رکورد از یک جدول ، در اختیار جدولِ دیگر هم هست) ، درون جدول مشترک تعریف میشوند . اما صفاتی را که مستقل هستند و فقط به یک جدول ربط دارند را فقط در همان جدول تعریف میکنیم .
یعنی صفاتی که هم مالِ جدولِ Student و هم مالِ جدولِ Lesson هست (یا متعلق به هر دو هست ، اما نه اینکه صرفا به هر دو جدول ، ربط داشته باشد) ، درون "جدول مشترک" تعریف میشوند.
مثلا :
صفتی مثل "نمره" ی درس ، فقط متعلق به یه دانشجوی خاص هست (یعنی یک نمره ی درس ، برای همه ی دانشجویان نیست ، بلکه فقط مربوط به یک رکورد خاصی از دانشجو هست) ، بنابراین صفت "نمره" را درون جدول مشترک تعریف میکنیم (یعنی داخل جدول درس ، تعریف نمیکنیم) .
اما صفاتی مثل "نام درس" که متعلق به (مالِ) دانشجوی خاصی نیست و همه ی دانشجویان ، آن درس را دارند ، پس صفت "نام درس" را فقط درون جدول درس ، تعریف میکنیم .
بنابراین صفاتی مثل زمان و مکان برگزاری امتحان ، که مربوط به دانشجوی خاصی نیست و مشترکا برای همه ی دانشجوها هست (یعنی همه ی دانشجوها ، در آن زمان یا مکان ، برای برگزاری امتحان ، حاضر میشوند) ، پس این صفات را هم درون جدول "درس" ، ذخیره میکنیم (درون جدول مشترک ، ذخیره نمیکنیم) .
حتی ممکنه که بعضی از این صفات ، باز بصورت مشترک با جدول استاد هم مشترک باشن که باز در جدولی مجزا نوشته میشن (در صورتی که رابطه ی چند به چند باشه) (البته بستگی به نیازمندی ها و طراحی هم داره) .
در مثالی دیگه که دو جدول "Person" و "Address" داریم و این دو جدول ، با هم رابطه ی چند به چند دارند و بنابراین جدول مشترکی بنام "PersonAddressLink" هم داریم ، اگر صفاتی مثل "استان" و "شهر" و "نشانی" و "نام آپارتمان" و "شماره واحد آپارتمان" و "شماره پلاک" و "کد پستی" را ذخیره کنیم ، همه ی این صفت ها ، درون جدول Address ذخیره میشن .
چون حتی صفت های "شماره پلاک" و "کد پستی" ، متعلق به شخص خاصی نیستند چون ممکنه که این صفت ها ، بصورت مشترک مربوط به اطلاعات یک خانواده که شامل چند شخص متفاوت هست ، باشه .
یعنی مثلا 3 شخص به عنوان یک خانواده ، مشترکا در یک خانه زندگی میکنند و بنابراین "شماره پلاک" و "کد پستی" مربوط به آن خانه ، برای همه ی این افراد بصورت مشترک مورد استفاده قرار میگیرد .
بنابراین ، این صفت ها باید درون جدول Address ذخیره شوند .
همچنین صفت های "نام آپارتمان" و "شماره واحد آپارتمان" هم مربوط به یک شخص خاص نیست . چون خانواده ها (و بنابراین اشخاص) مختلفی درون آن آپارتمان و حتی درون یک واحد از آپارتمان زندگی میکنند .
البته همین ارتباطات در این جدول های Person و Address و PersonAddressLink ، اگر برای سناریوی مالک ساختمان باشد ، یعنی اگر بجای جدول Person ، جدول Owner داشتیم ، در این حالت ، چون هر صفت از "شماره پلاک" و "کد پستی" ، مربوط به فقط یک شخص خاص (که آن هم مالک ساختمان هست) ، میشود و بصورت مشترک توسط چندین شخص نمیتواند استفاده شود ، پس در این سناریو ، این دو صفت را درون جدول PersonAddressLink باید ذخیره کنیم چون این اطلاعات ساختمان ، مربوط به یک شخص خاص هست (نه مربوط به چندین شخص) .