saalek110
Well-Known Member
رگولار اکسپرژن ، آشنایی
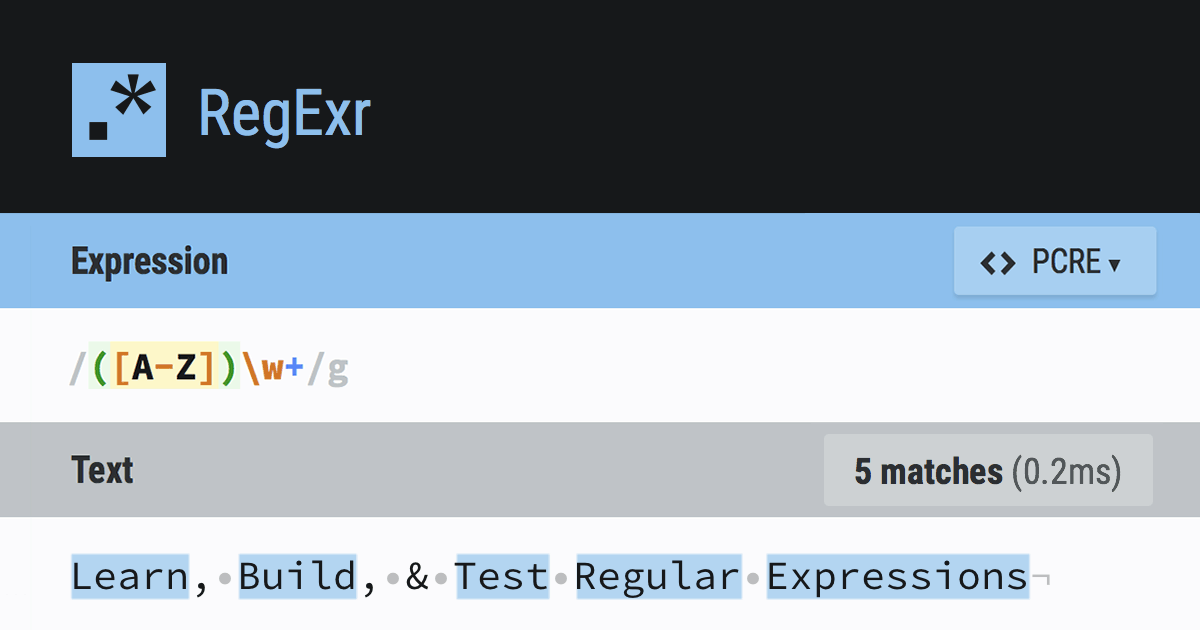
رگولار اکسپرژن برای حروف فارسی
 forum.majidonline.com
forum.majidonline.com
تاپیک بعدی ، مرور رگولار اکسپرژن:
forum.majidonline.com
رگولار اکسپرژن برای حروف فارسی
رگولار اکسپرژن برای حروف فارسی
رگولار اکسپرژن برای حروف فارسی آموزش رگولار اکسپرژن را ابتدا یاد بگیرید و سپس این تاپیک را بخوانید. تاپیک زیر: https://forum.majidonline.com/threads/%D8%B1%DA%AF%D9%88%D9%84%D8%A7%D8%B1-%D8%A7%DA%A9%D8%B3%D9%BE%D8%B1%DA%98%D9%86-%D8%8C-%D8%A2%D8%B4%D9%86%D8%A7%DB%8C%DB%8C.240817/
تاپیک بعدی ، مرور رگولار اکسپرژن:
رگولار اکسپرژن ، مرور و تمرین
رگولار اکسپرژن ، مرور و تمرین تاپیک قبلی: https://forum.majidonline.com/threads/%D8%B1%DA%AF%D9%88%D9%84%D8%A7%D8%B1-%D8%A7%DA%A9%D8%B3%D9%BE%D8%B1%DA%98%D9%86-%D8%8C-%D8%A2%D8%B4%D9%86%D8%A7%DB%8C%DB%8C.240817/
آخرین ویرایش: